GCSE
Biology
-
Introduction to GCSE Biology (AQA) Coming soon
-
1.1 Cell Structure
-
1.2 Cell Division Coming soon
-
1.3 Transport in Cells Coming soon
-
2.1 Principles of Organisation Coming soon
-
2.2 Animal Tissues, Organs and Organ Systems Coming soon
-
2.3 Plant Tissues, Organs and Systems Coming soon
-
3.1 Communicable Diseases Coming soon
-
3.2 Monoclonal Antibodies [HT] Coming soon
-
3.3 Plant Disease Coming soon
-
4.1 Photosynthesis Coming soon
-
4.2 Respiration Coming soon
-
5.1 Homeostasis Coming soon
-
5.2 The Human Nervous System Coming soon
-
5.3 Hormonal Coordination in Humans Coming soon
-
5.4 Plant Hormones Coming soon
-
6.1 Reproduction Coming soon
-
6.2 Variation and Evolution Coming soon
-
6.3 The Development of Understanding of Genetics and Evolution Coming soon
-
6.4 Classification of Living Organisms Coming soon
-
7.1 Adaptations, Interdependence and Competition Coming soon
-
7.2 Organisation of an Ecosystem Coming soon
-
7.3 Biodiversity and the Effect of Human Interaction on Ecosystems Coming soon
-
7.4 Trophic Levels in an Ecosystem Coming soon
-
7.5 Food Production Coming soon
1. Cell Biology
In this lesson, we will explore the structureThe organisation and order of information in a text. of DNA, focusing on its composition as a polymer made from nucleotides and the role of nucleotides in determining the genetic code. We will also discuss how genetic variants can influence phenotype and protein activity, and we will explore mutations and the role of non-coding DNA in gene expression.
DNA as a Polymer
DNA (deoxyribonucleic acid)The molecule carrying genetic instructions used in the growth, development, functioning, and reproduction of all living organisms. is a long polymer composed of repeating units called nucleotides. Each nucleotideThe basic building block of DNA and RNA, consisting of a sugar, phosphate, and base (A, T, G, or C). consists of three components:
- Sugar: DNA contains a sugar molecule called deoxyribose.
- Phosphate Group: A phosphate group is attached to the sugar molecule.
- Base: One of four different bases (adenine, cytosine, guanine, or thymine) is also attached to the sugar molecule.
Composition of DNA
- Nucleotides: DNA is formed by joining nucleotides together in a specific sequence.
- Four Bases: DNA contains four different bases: adenine (A), cytosine (C), guanine (G), and thymine (T).
- Base Pairing: The bases in DNA form complementary pairs:
- Adenine (A) pairs with thymine (T) through two hydrogen bonds.
- Cytosine (C) pairs with guanine (G) through three hydrogen bonds.
- This complementary base pairing is essential for DNA replication and maintaining the structure of the double helix.
Genetic Code
- Amino Acids and Proteins: Amino acids are the building blocks of proteins, and proteins play essential roles in the structure and function of cells.
- Codons: A sequence of three DNA bases, known as a codon, codes for a specific amino acid.
- Genetic Code: The order of the bases in DNA determines the order in which amino acids are assembled during protein synthesisCombining information from more than one text to show comparison..
- Central Dogma: The flow of genetic information follows the central dogma of molecular biology:
- DNA is transcribed into RNA (ribonucleic acid) through a process called transcription.
- RNA is then translated into proteins through a process called translation.
DNA Structure
- Double Helix: DNA (deoxyribonucleic acid) is a double-stranded molecule that forms a twisted ladder-like structure known as a double helix.
- Sugar-Phosphate Backbone: The backbone of the DNA molecule is composed of alternating sugar and phosphate sections. The sugar in DNA is called deoxyribose, and the phosphate groups connect the sugars together.
- Nucleotide Bases: Attached to each sugar molecule in the DNA backbone is one of four nitrogenous bases: adenine (A), cytosine (C), guanine (G), or thymine (T).
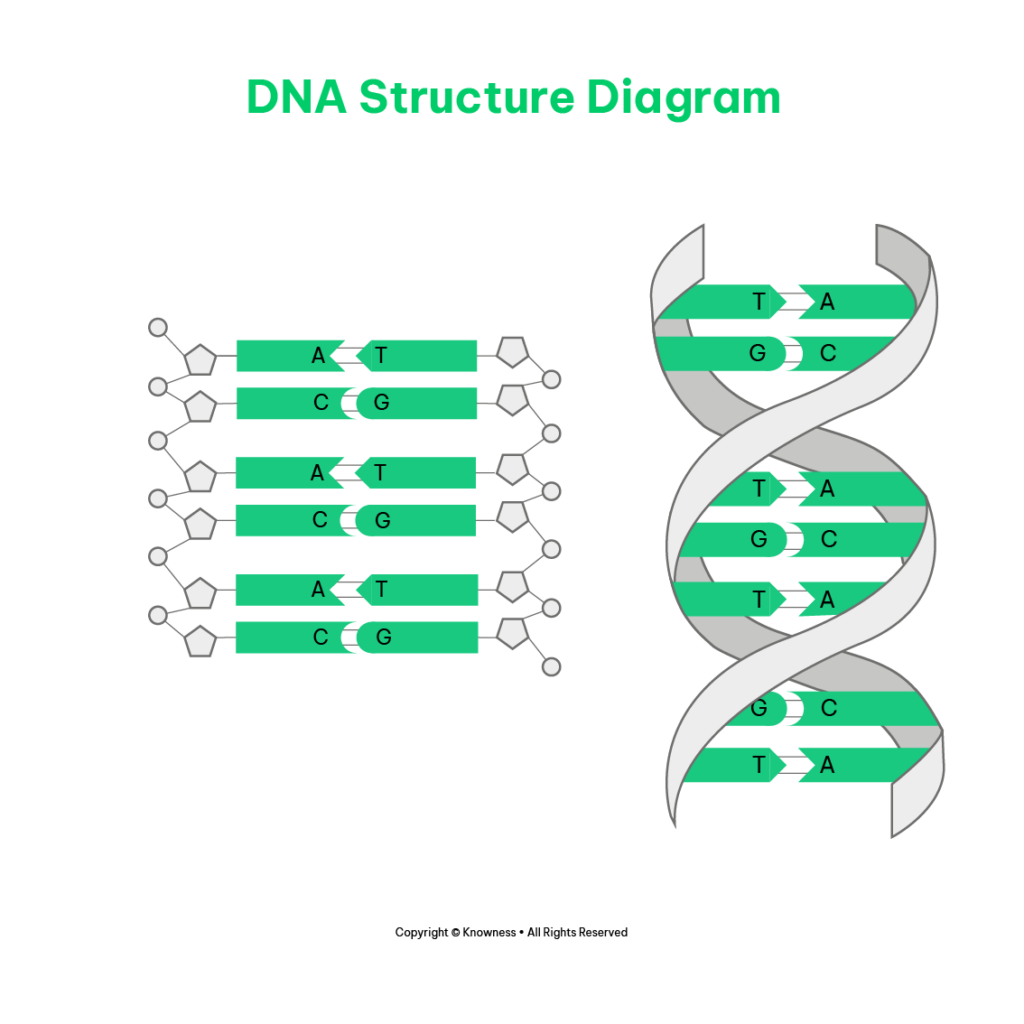
Nucleotide Units
- Nucleotides: DNA is formed by joining nucleotide units together.
- Composition of Nucleotides: Each nucleotide consists of three components:
- Sugar: DNA contains the sugar deoxyribose.
- Phosphate Group: A phosphate group is attached to the sugar.
- Base: One of the four nitrogenous bases (A, C, G, or T) is attached to the sugar.
DNA Polymer
- DNA Strand: Each DNA strand is composed of a linear sequence of nucleotides.
- Complementary Base Pairing: The two DNA strands are held together by complementary base pairing:
- Adenine (A) forms hydrogen bonds with thymine (T), creating an A-T base pair.
- Cytosine (C) forms hydrogen bonds with guanine (G), creating a C-G base pair.
- This complementary base pairing ensures the stability and integrity of the DNA molecule.
Protein Synthesis (HT only)
Protein synthesis is the process by which cells create proteins using the instructions encoded in DNA. The structure of DNA plays a crucial role in determining the protein that is synthesised.
DNA Structure and Protein Synthesis (HT only)
In DNA, the bases adenine (A) always pairs with thymine (T), and cytosine (C) always pairs with guanine (G). This complementary base pairing is essential for DNA replication and transcription. Genes are segments of DNA that contain instructions for building specific proteins.
- Transcription: The first step of protein synthesis is transcription, where a section of DNA is copied into a molecule called messenger RNA (mRNA).
- mRNA and Protein Production: The mRNA carries the genetic code from the DNA in the nucleusA membrane-bound organelle in eukaryotic cells that contains DNA. to the ribosomes in the cytoplasmA jelly-like substance in cells where most chemical reactions occur.. At the ribosomes, the genetic code is translated, and proteins are synthesised.
- Translation: During translation, transfer RNA (tRNA) molecules bring specific amino acids to the ribosomeA small structure in cells where proteins are made.. The sequence of the mRNA is read, and the appropriate amino acids are joined together to form a protein chain.
- Protein Folding: After the protein chain is synthesised, it folds into a unique three-dimensional shape. The specific shape is essential for the protein to carry out its function.
Genetic Variants and Phenotype (HT only)
- Coding DNA: Genetic variants in coding DNA can alter the activity of a protein. Changes in the DNA sequence may lead to different amino acids being incorporated into the protein chain, affecting its structure and function.
- Non-coding DNA: Genetic variants in non-coding DNA can influence gene expression. These variants can affect the regulation of gene activity, leading to changes in the amount or timing of protein production.
Mutations (HT only)
- Continuous Occurrence: Mutations are changes in the DNA sequence that occur continuously.
- Protein Alteration: Most mutations do not significantly affect the protein or its function. Some mutations may only cause slight changes that do not impact the appearance or function of the protein.
- Altered Protein Shape: However, a few mutations can lead to the production of an altered protein with a different shape.
- Enzyme-Substrate Interaction: In some cases, the mutation may affect the enzyme's shape, making it unable to properly bind to its substrate.
- Structural Proteins: Mutations in structural proteins can lead to a loss of strength or integrity in the protein's structure.
Non-Coding DNA and Gene Expression (HT only)
- Non-Coding DNA: Not all parts of the DNA sequence code for proteins. Non-coding DNA refers to regions of the genome that do not contain protein-coding genes.
- Gene Regulation: Non-coding DNA plays a crucial role in gene regulation by controlling the on/off switch of genes.
- Gene Expression: Variations in non-coding regions of DNA can affect how genes are expressed, influencing the production of proteins.
- Enhancers and Repressors: Non-coding DNA may contain regulatory elements like enhancers and repressors, which interact with specific proteins to activate or inhibit gene expression.
- Epigenetic Modifications: Chemical modifications of non-coding DNA can also influence gene expression by altering the accessibility of genes to the cellular machinery responsible for transcription.
Conclusion
DNA, a polymer consisting of nucleotides with sugar, phosphate, and four different bases, holds the key to genetic information. The sequence of these bases in DNA dictates the genetic code, controlling the order of amino acids assembled into proteins, which are essential for cell structure and function. DNA's double-helix structure, with sugar-phosphate backbones and attached bases, encodes and transmits genetic data. This structure also enables complementary base pairing, facilitating DNA replication and trait inheritance. DNA's role extends to guiding protein synthesis through genes within its structure. Mutations, whether in coding or non-coding regions of DNA, can profoundly affect protein function and expression, thus influencing an organism's traits and functions. Furthermore, non-coding DNA regions play a crucial role in gene regulation, impacting when genes are activated or deactivated, consequently affecting protein production.
Continue the lesson
This section is available to learners with course access. Continue learning with Knowness to unlock the full explanation, examples, revision tools, and progress tracking.
The remaining lesson content includes further guided explanation, important learning points, and supporting interactive material designed to help you understand and revise this topic.
Unlock this topic to view the full activity, worked examples, common mistakes, and additional revision support.
More content available
Knowness lessons are structured to build understanding step by step. Create an account or upgrade your access to continue from this point.
This preview does not include the hidden lesson text, answers, explanations, or embedded interactions.
Continue learning with Knowness
Sign up to access the full lesson, predicted grades, revision tools, progress tracking, and more.
Create a free account