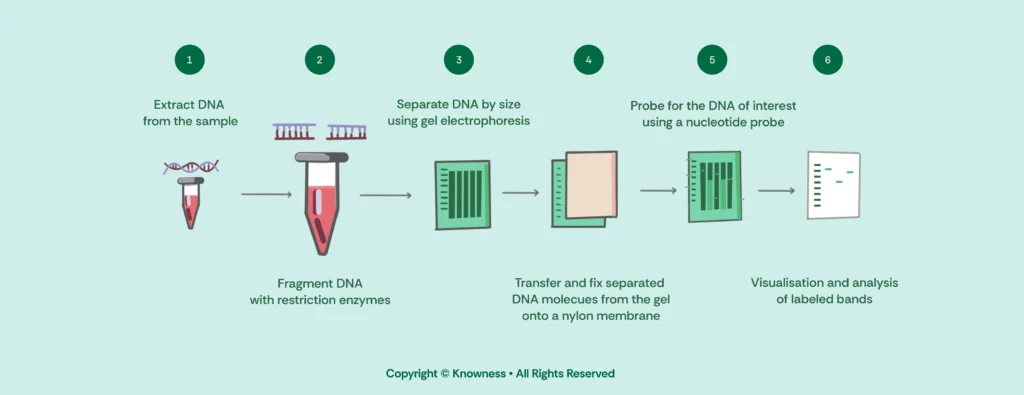
2.1 What is DNA?
DNA stands for deoxyribonucleic acid. The molecule is composed of deoxyribose sugar, a sugar phosphate backbone and nitrogenous bases which wind together in a double helical structureThe organisation and order of information in a text.. These nitrogenous bases (adenine, thymine, guanine and cytosine) are held together by weak hydrogen bonds.
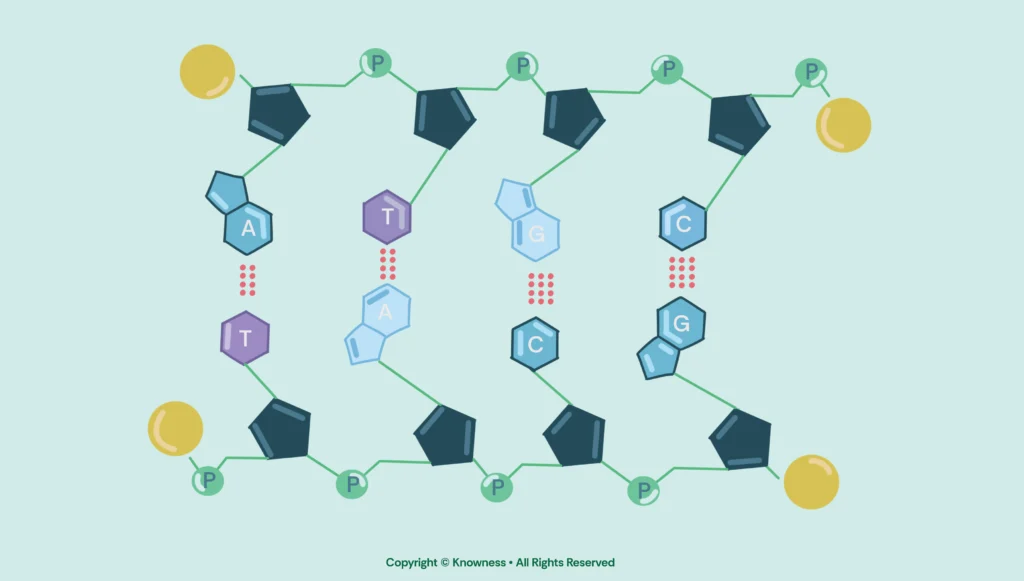
A-T and G-C are complementary because of their shape and bonding properties, which allow them to fit together perfectly within the double helix structure of DNA. Specifically, adenine (A) pairs with thymine (T), and guanine (G) pairs with cytosine (C).
The difference in hydrogen bonds—3 for G-C and 2 for A-T—stems from the chemical structure of the bases. Guanine and cytosine each have three available bonding sites that align, enabling three hydrogen bonds to form, which adds stability to the DNA. Adenine and thymine, on the other hand, have only two bonding sites that align, so they form two hydrogen bonds. This difference in bonding capacity and resulting stability is crucial to the uniform width and structure of the DNA double helix.
These bases form our genes; an instructional manual, containing your building blocks to your individuality, which is unique to you (unless you’re an identical twin).
Speaking of genes, let's run you through the process of protein synthesisCombining information from more than one text to show comparison.; how genes become us:
Step 1
Since our DNA is too precious to leave our membrane bound nucleusA membrane-bound organelle in eukaryotic cells that contains DNA., a single strand is synthesised within the nucleus, but with one significant change; the nitrogenous base thymine is now replaced by uracilA nucleotide base not normally found in DNA (present in RNA), often resulting from the deamination of cytosine in ancient DNA.. This strand containing uracil is known as messenger RNA (mRNA). The enzymeA biological catalyst that speeds up chemical reactions in cells. RNA polymerase unwinds the double helix by attaching to a promoter region of the DNA, exposing the strands. One strand is the template strand, which will form the basis of the novel strand.
RNA polymerase moves up the template strand, adding nucleotides (adenine, uracil, cytosine and guanine) to the novel strand of mRNA, with the mRNA strand increasing in length from the 5’ to 3’ prime end.
Now, when RNA polymerase reaches a sequence of nucleotides on the template strand which the enzyme recognises to be the termination sequence, the addition of further nucleotides will cease; pre-mRNA has now been formed.
In eukaryotes, this pre-mRNA undergoes additional processing:
- A 5’ cap (a modified guanine nucleotideThe basic building block of DNA and RNA, consisting of a sugar, phosphate, and base (A, T, G, or C).) is added to the start of the mRNA.
- A poly-A tail (a series of adenine nucleotides) is added to the 3” end.
- Splicing removes the non-coding regions of RNA called introns, leaving only the coding regions called exons.
Once processed, the mature mRNA exits the nucleus via nuclear pores and enters the cytoplasmA jelly-like substance in cells where most chemical reactions occur., where the next stage takes place. The entirety of this process which occurs in the nucleus is known as transcription.
Step 2
Now that a mature mRNA strand has been formed, it leaves the nucleus via a nuclear pore and moves out into the cytoplasm to find a ribosomeA small structure in cells where proteins are made. to attach itself to. The mRNA will attach itself to the ribosome, ensuring that it is attached where the start codon is located (AUG).
A specific transfer RNA (tRNA) molecule, carrying the amino acid methionine (which corresponds to the start codon AUG), binds to the start codon on the mRNA through its anticodon. The large ribosomal subunit then joins the small subunit, forming a complete ribosome ready for translation. The ribosome moves along the mRNA strand in the 5' to 3' direction, reading each codon (a sequence of three mRNA bases). For each codon, a corresponding tRNA molecule with a matching anticodon brings the appropriate amino acid to the ribosome.The amino acids are linked together by peptide bonds to form a growing polypeptide chain.
The ribosome has three important sites:
- A site (Aminoacyl site): where the tRNA carrying the next amino acid binds.
- P site (Peptidyl site): where the tRNA holding the growing polypeptide chain is located.
- E site (Exit site): where tRNA, having delivered its amino acid, exits the ribosome.
Each new tRNA arrives at the A site, and the amino acid it carries is transferred to the growing chain at the P site, with the ribosome shifting along the mRNA.
Elongation continues until the ribosome encounters a stop codon (UAA, UAG, or UGA) on the mRNA. These stop codons do not code for any amino acids and instead signal the ribosome to release the completed polypeptide chain. Then, release factors bind to the ribosome, prompting it to disassemble, releasing both the mRNA and the newly formed polypeptide. The entirety of this process is known as translation.
Now that the polypeptide chain has been formed, the chain will undergo further post translational modifications, in order for the polypeptide to be turned into a fully functioning protein:
- Folding: The polypeptide chain is folded into the differing structure types proteins have (primary, secondary, tertiary and quaternary), with the aid of chaperone proteins.
- Post-Translational Modifications:
- Cleavage: Some proteins are split into smaller active forms, via the process of being cut up into smaller proteins.
- Chemical Modifications: Phosphate groups (phosphorylation), sugars (glycosylation), or lipids may be added, affecting the protein's function or location, allowing them to take on more versatile roles.